New Distributed File System Storage
Following the power outage our datacenter experienced on December 8th, a few weaknesses became apparent in our infrastructure, the most important one being our storage model. Even with a SAN, there still is a Single Point of Failure and in case of a power outage, doing a full system integrity check can take multiple days when dealing with our volume of data.
With that in mind we set out to solve both issues: data redundancy and post-outage recovery. We settled on two major changes which addressed this problem:
- We converted all our storage file systems to ZFS which requires no integrity check post-outage. We already had a few backup systems running ZFS prior to the outage and it’s thanks to them that there was no data loss.
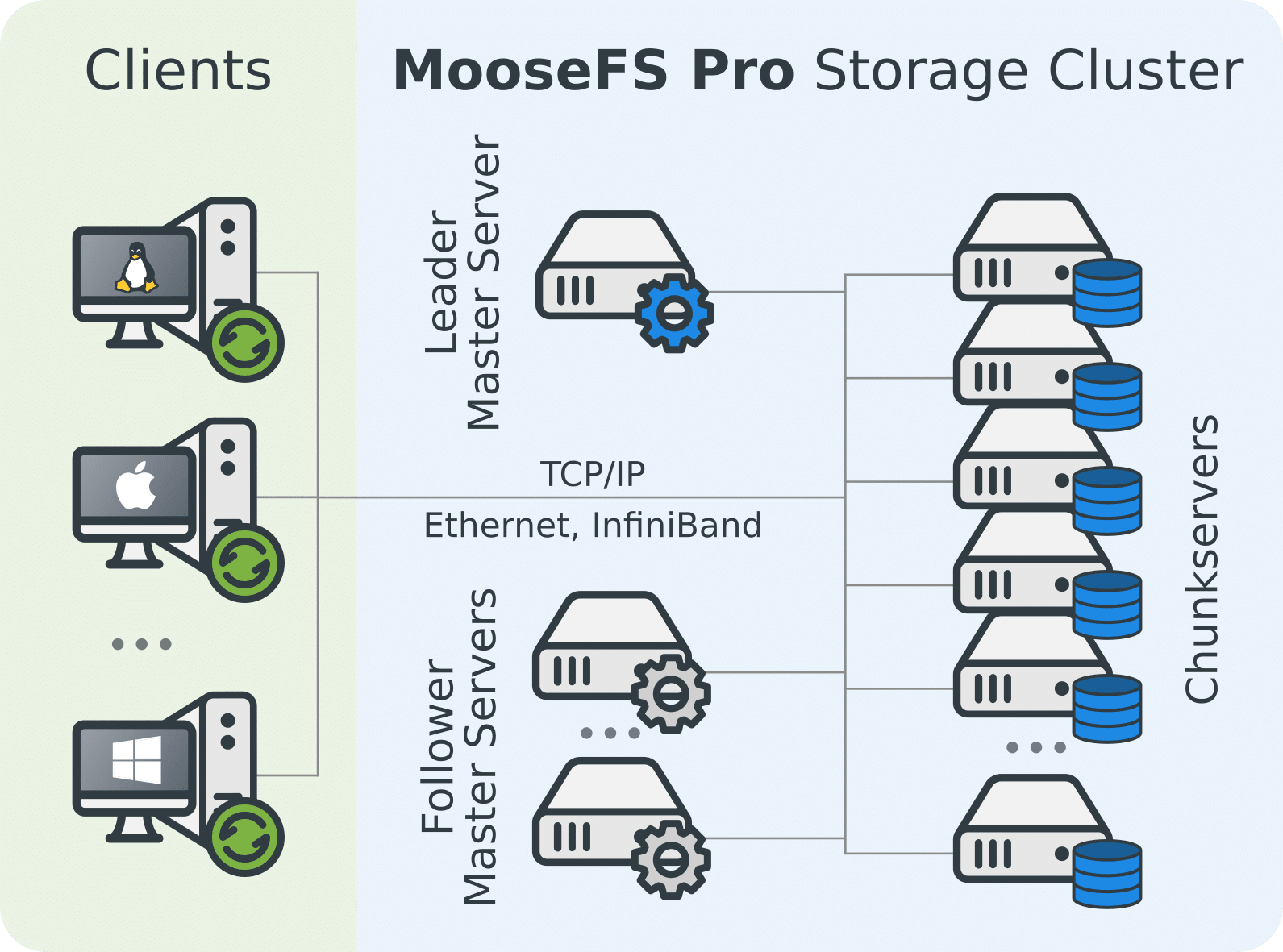
- We started deploying MooseFS PRO as a Distributed File System on all our storage servers. This eliminated the Single Point of Failure we previously had, as now copies of each data block resides on multiple servers.
With this new storage model we not only have redundancy within each server via mirrored disks, but we also have redundancy at the server level, meaning that an entire server can fail without loss of data access. Furthermore, in case of a power outage, the recovery time is lowered to mere minutes instead of hours or days.
Furthermore, this model allows us to add storage capacity on the fly, set higher redundancy ( ability to store more than two copies of the data ) and also distribute our data geographically in order to mitigate against local problems or to meet new regulations – EU data could reside in a EU server and be served locally.
We are now ready to grow on much more solid foundations and although it was a challenging past few months, it was definitely worth the effort!

Sign up for a 30 days free trial of our e-mail services.